The question "AI or coach?" has been circulating in every fitness forum since ChatGPT arrived. What rarely happens: a look at the actual research. Yet there is now a growing number of peer-reviewed studies examining exactly this — with surprisingly sober results. Researchers agree on one point: the quality of an AI training plan depends directly on what you give the AI. On another point the research hasn't reached consensus yet, because no one has asked the decisive question. This article shows what the evidence actually supports — and where the studies stop.

AI vs. Coach: What Studies Actually Show
At a glance
More context in the prompt means significantly better AI plans — Düking et al. (2024) show this reproducibly. AI outperformed personal trainers at answering training questions, but not at creating or adapting plans (D'hoe et al. 2026). The basic structure in strength training is solid; individual progression remains the consistent weak point. And the real research gap: how well AI adapts a plan over weeks has not been studied yet.
Stay on top of AI training & analysis? One click — and Google shows you my articles first.
Add as a preferred source on GoogleWhat research on AI training plans actually measures — and what it doesn't
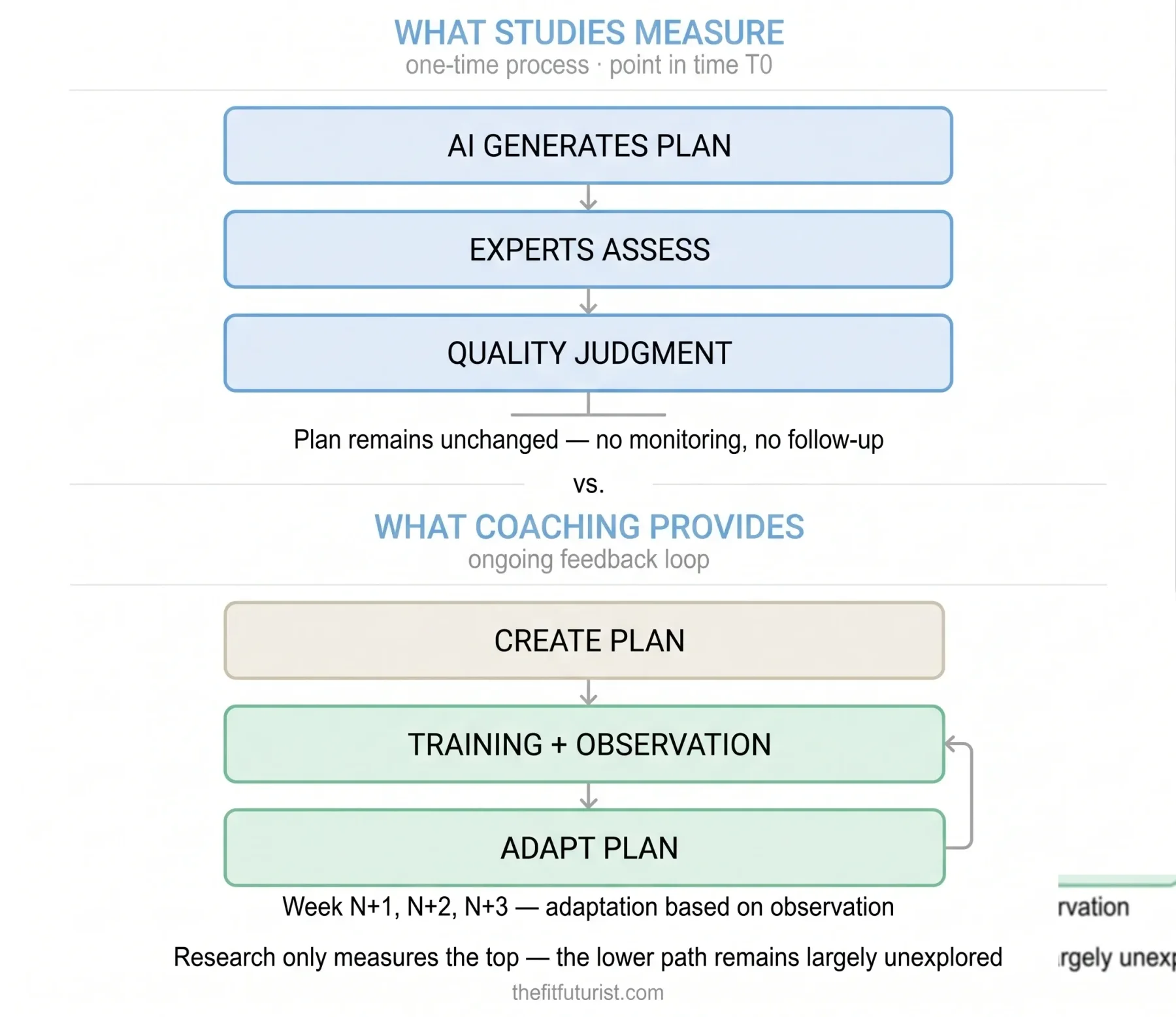
When studies evaluate the quality of AI training plans, they almost always follow the same pattern: an AI generates a plan, coaching experts rate it against a set of criteria. Sometimes AI plans are compared directly with human-made ones, sometimes they are checked against established guidelines (NSCA, ACSM).
What is consistently missing: the time dimension. What happens in week 4 when the athlete stagnates? Who notices that sleep and stress require a training adjustment? Who replans when a session is missed?
This dynamic dimension — the core of real training support — is not the subject of measurement in any study published so far. The research evaluates AI training plans at time T0. What happens after T0 remains methodologically unanswered.
That is not a small gap. It is the difference between a written plan and real coaching.
Prompt depth is decisive: what the Düking study (2024) shows
The most-cited investigation on this topic comes from Düking et al., published in 2024 in the Journal of Sports Science and Medicine. Ten coaching experts evaluated three six-week ChatGPT-generated running plans against 22 quality criteria — the three plans coming from prompts of differing information density.
The result is clear: Plan 3, created with the most detailed input, significantly outperformed Plan 1 on 15 of 22 criteria. That is not a marginal effect — it is a structural difference in plan quality.
But even the best plan had a consistent weak point: the progression of training volume received a below-average rating even with the most detailed prompt. The authors also explicitly noted that ChatGPT asked no follow-up questions — the way a coach would, to capture the athlete's preferences, fatigue or risk tolerance.
That is the decisive finding behind the numbers: good prompts improve AI plans enormously. But the best prompt does not replace a coach's ability to ask, over the course of training, questions the athlete didn't even know to ask.
An experienced coach gathers information in the first weeks that the athlete never explicitly communicated — a changed movement pattern, shorter recovery times between sets, a casual remark about poor sleep. Exactly these signals are missing from the prompt — because you would have to notice them yourself before you could type them in.
This is exactly the approach of the Claude training plan skill: before Claude plans anything, the skill runs a structured assessment — training history, goal, injuries, available time, equipment. And it doesn't stop at the first plan: after every training week Claude reads your training log, recognises patterns and adjusts. The same pain twice triggers a plan modification, three times triggers a recommendation to see a physiotherapist. Whether this works in practice the way it's intended — that still has to be seen. So: use the skill, give feedback, and help make it better.
The remaining difference to a human coach is subtler: the skill reacts to what you enter. An experienced coach also observes what you don't communicate — a changed movement pattern, shorter breaks between sets, a casual remark about poor sleep. These signals are missing from the log because you would have to notice them yourself first.
AI beats coaches — but at questions, not at plans
A 2026 study, also published in the Journal of Sports Science and Medicine, delivered widely discussed results: in a direct comparison with nine human personal trainers (EQF Level 4), ChatGPT scored better on 6 of 9 questions — rated on scientific correctness, comprehensibility and practicability. On not a single question did the trainers outperform the AI.
That sounds devastating for the coaching side. Methodologically, however, what matters is what was actually measured: D'hoe et al. (2026) tested the ability to answer common training questions — not to create, monitor or adapt plans. As an information source, ChatGPT outperforms the average personal trainer at the evidence-based retrieval of training recommendations. That is a real and relevant finding.
What it does not prove: that AI creates a good individual training plan, guides it over weeks, or detects warning signs.
Study | What was measured | Result |
|---|---|---|
D'hoe et al. 2026 | AI vs. coaches: common training questions | AI rated better on 6 of 9 questions |
Düking et al. 2024 | ChatGPT running plans by prompt depth | More input = significantly better plan quality |
Washif et al. 2024 | ChatGPT strength programmes vs. NSCA guidelines | Basic structure compliant, fine-tuning needed |
Genç et al. 2025 | ChatGPT 3.5, 4o and 4.1 compared | Structure okay, individual adaptation limited |
Strength training with AI: structure yes, progression with caveats
Washif et al. (2024) had GPT-3.5 and GPT-4 create twelve-week strength programmes for hypothetical subjects and compared them with NSCA guidelines. The basic verdict: the programme structure was solid. Progressive overload, training frequency and phase distribution were within the expected range. GPT-4 performed notably better than GPT-3.5 — more contextual awareness, finer differentiation between training levels.
What fell short: GPT-3.5 recommended the same rest intervals across all training phases — a specificity error that would be suboptimal in a real programme. Neither model version systematically addressed proximity to muscular failure, which modern hypertrophy research treats as a relevant control variable.
Genç et al. (2025) compared three ChatGPT versions (3.5, 4o, 4.1) with a similar study design. Their conclusion: newer models also show limitations but benefit strongly from structured, principle-oriented prompts. For standard populations the output is usable — for advanced athletes with specific goals, human expertise remains a real added value.
What studies don't measure — the blind spot of the research
All studies published so far share a design feature: they measure the AI training plan at the moment of its creation. An expert rates whether the plan is good. Done.
What no one has measured: how does AI behave when the athlete isn't making the expected progress after three weeks? When sleep, stress or life circumstances change? When a minor injury alters the programme for weeks?
Düking et al. (2024) named this implicitly: ChatGPT asked no follow-up questions. That is not a bug — it is a structural feature of the medium that current research only measures during plan creation, not during the navigation of reality afterwards.
The question "Can AI adapt a training plan as well as a coach?" is scientifically unanswered. Not because the answer is unclear, but because no one has yet carried out a longitudinal study with this design. That is the single largest open research gap in the whole field of AI training planning.
What the evidence specifically means — and where it stops
The body of evidence is young, methodologically heterogeneous, and covers only a small slice of training reality. What it nevertheless shows clearly: AI-generated training plans can deliver a solid initial structure for standard populations with good prompts — reproducibly across several studies.
What is systematically underestimated: the usefulness of AI training plans depends directly on the competence of the user. Someone who understands the fundamentals of training planning writes better prompts — and evaluates the output critically enough to spot mistakes. That is no coincidence; that is the core of the prompt paradox: the AI is only as good as the knowledge you give it.
What the research also shows: the gap between good AI planning and human coaching is smaller at the initial plan stage than many expect. How big it becomes over eight or twelve weeks, when real adaptation is needed — science simply doesn't know yet.
If you want to start with a self-created AI training plan, this is the starting point — not as a shortcut around thinking, but as a tool you know how to use. Or jump straight in: generate a training plan for free — assessment included.
Frequently Asked Questions
Which studies compare AI training plans with human coaches directly?
The currently most relevant studies are Düking et al. (2024) on ChatGPT running plans (JSSM, DOI: 10.52082/jssm.2024.56), D'hoe et al. (2026) on the comparison of training questions (JSSM, PMC12912680), Washif et al. (2024) on strength programmes (Biology of Sport, DOI: 10.5114/biolsport.2024.132987), and Genç et al. (2025) comparing different ChatGPT versions (BMC Sports Sci Med Rehabil, DOI: 10.1186/s13102-025-01409-7). All are available open access.
Are AI training plans worse than those made by coaches?
That depends on the criterion. On standardised structures (frequency, volume, phasing), modern AI models with good prompts deliver solid results. On individual adaptation over weeks there is no robust data — that question has not been investigated yet.
Why is prompt quality so decisive?
All studies show consistently: more precise information in the prompt leads to significantly better plan quality. AI works exclusively with what you give it. Someone who knows the fundamentals of training planning can write more precise prompts — and gets more precise results.
Are there studies on long-term AI training support?
No. That is the biggest open gap in current research. So far only the initial plan quality at the time of creation has been investigated — the adaptation performance over weeks and months remains methodologically unexplored.


