Your body produces data during training. Heart rate, pace, power, sleep quality, muscle activation. The question isn't whether you use it — it's how.
Fitness trackers, smartwatches and apps today collect more training data than any sports lab did ten years ago. At the same time, algorithms promise to turn this data into "personalised" training recommendations. Some are useful. Many are marketing.
This page is the starting point for everything Training and Analysis on TheFitFuturist. Here I classify what data-based training really means — from practice, not from the marketing department.
At a glance
Training & Analysis connects training practice with technology. The articles in this category show how AI, data analysis and modern tools can concretely improve your training — and where you're better off trusting your own judgement than an algorithm.
Data-based training: more than step counting
Data-based training sounds like pro sport. Like VO2max tests in the lab, lactate thresholds and performance diagnostics. In reality, anyone with a smartwatch on their wrist is already using a basic form of it — often without knowing.
The problem: most users collect data without understanding it. They see a number — training status "Unproductive", Recovery Score 43%, estimated VO2max 47 — and don't know what to do with it. Or worse: they blindly trust a number that's based on estimates.
NOTHING NEW: THE LACTATE EXAMPLE
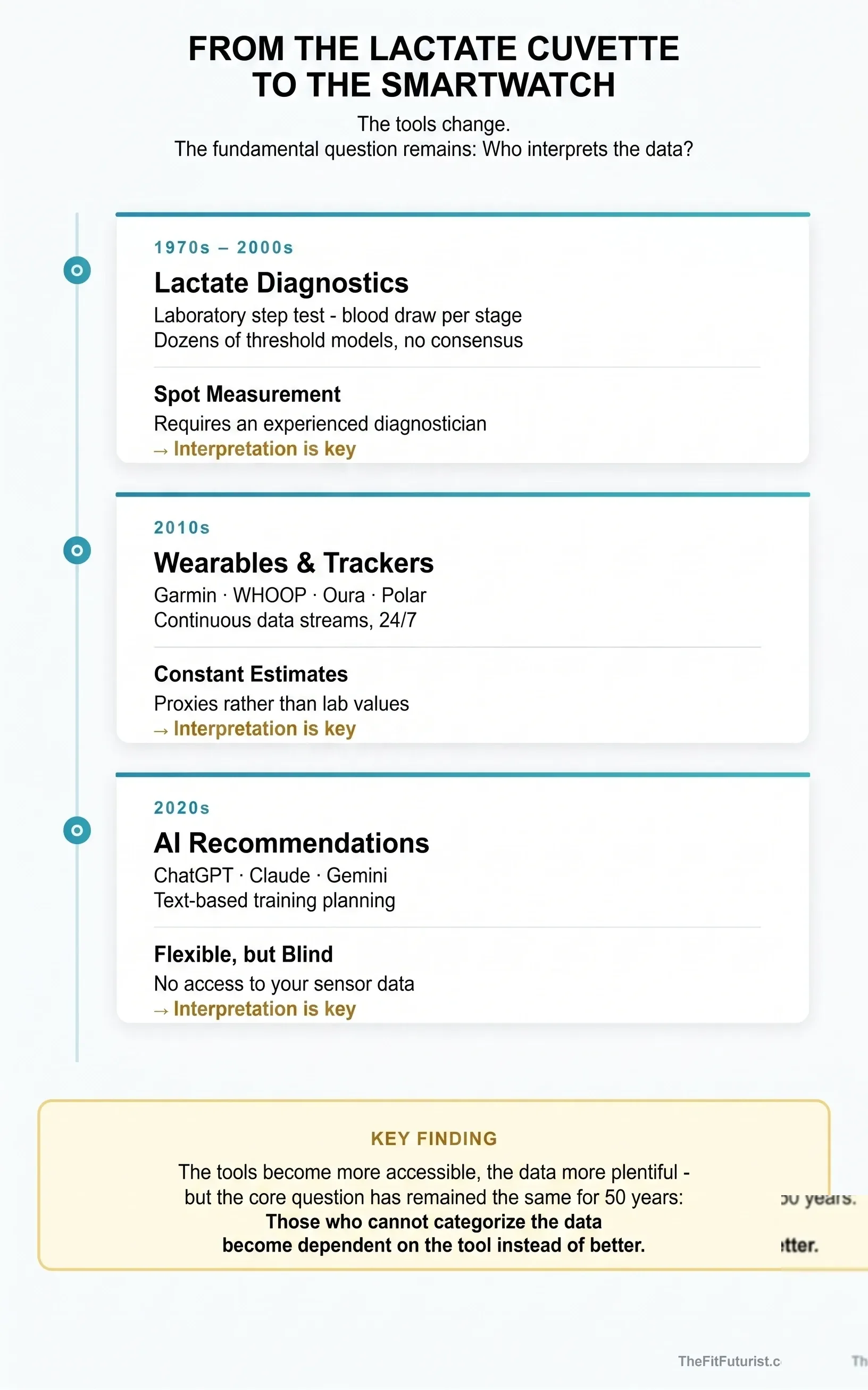
The debate about diagnostic tools is older than any smartwatch. Lactate diagnostics — the standard procedure for endurance performance diagnostics since the 1970s — has had its validity questioned from the start. Dozens of threshold models leading to different results. The question of whether "the" anaerobic threshold even exists as a fixed point, or whether the transitions are fluid. When I studied sport science, this was already an ongoing topic — and still is today. Lactate diagnostics nevertheless remains a valuable tool. Not because it's perfect, but because an experienced diagnostician can classify the results and use them for training management.
Diagnostic tools have always had their limits and critics. What mattered was never the tool itself, but whether the person using it knew what they were measuring, when the measurement made sense, and how to interpret the results. With lactate values that was the case. With smartwatch metrics it's no different. And with AI-generated training recommendations, even more so.
At its core, data-based training means systematically managing load and recovery. The basic principles — supercompensation, periodisation, progressive overload — have existed for decades. What has changed is data availability. Where coaches used to rely on subjective feeling and occasional tests, wearables today deliver continuous streams. Heart rate variability during sleep, stride frequency while running, force curves on the barbell.
The decisive question isn't whether this data exists. It's whether the algorithms interpreting it work on sound scientific grounds — or are just well-packaged heuristics.
Where AI actually helps — and where it doesn't
Artificial intelligence in training is not a single concept. Under the "AI" label, completely different technologies are lumped together: rule-based algorithms, statistical models, machine learning and large language models. The fitness industry rarely distinguishes between these categories. TheFitFuturist does.
Adaptive training algorithms, as used by Garmin, WHOOP or Polar, mostly work with statistical models. They compare your data with that of a reference population and derive recommendations from it. That works solidly for average values, but hits limits as soon as you're not average — that is, with advanced users, pre-existing conditions, or unusual training goals.
Large language models like ChatGPT or Claude bring a different approach. They understand training concepts as text and can build plans, classify data or answer questions based on those concepts. Their strength lies in flexibility — you can describe your individual situation and get a tailored answer. Their weakness: they have no access to your actual training data, can't "feel" how you feel after a session, and occasionally hallucinate studies that don't exist.
Training planning between algorithm and experience
Creating a training plan requires the interplay of training science, individual assessment and practical experience. No algorithm in the world replaces this interplay completely — but it can take over parts of it.
The biggest added value of AI-supported training planning lies with beginners and returners. Anyone without experience in periodisation will get a more structured plan from an LLM than from Google and YouTube combined. Provided the prompt is right. And this is exactly where the prompt paradox kicks in: those who know little about training ask bad questions — and still get a confident answer.
For advanced athletes, the usefulness shifts. Here AI is less valuable as a plan creator and more as a sparring partner: discussing periodisation models, generating alternatives to stagnating programs, explaining scientific concepts. Control stays with the athlete — the tool delivers input, not instructions.
What that looks like in practice — with copy-and-paste prompts for strength, endurance and hybrid training — is in the guide Create a training plan with AI.
Performance analysis: what your data really says
VO2max estimates from smartwatches deviate on average by 5–15% from the actual lab value. They're still useful — if you classify them correctly. The absolute value is less relevant than the trend over weeks and months.
That applies to most metrics wearables deliver today. Your Body Battery Score, your Training Readiness Index, your Sleep Score — they are estimates based on limited sensor data. Useful as orientation, dangerous as dogma. Anyone who doesn't train in the morning because a number on the display is red has made the tool their boss.
Meaningful analysis begins with the right question. Not "What does my score say?" but "Which hypothesis can I test with my data?" Am I overtraining? Is my aerobic base improving? Do I need more recovery? Data provides clues, not answers. Interpretation remains the job of the thinking human — whether with or without a degree.
When the watch becomes the coach: the problem of algorithm dependence
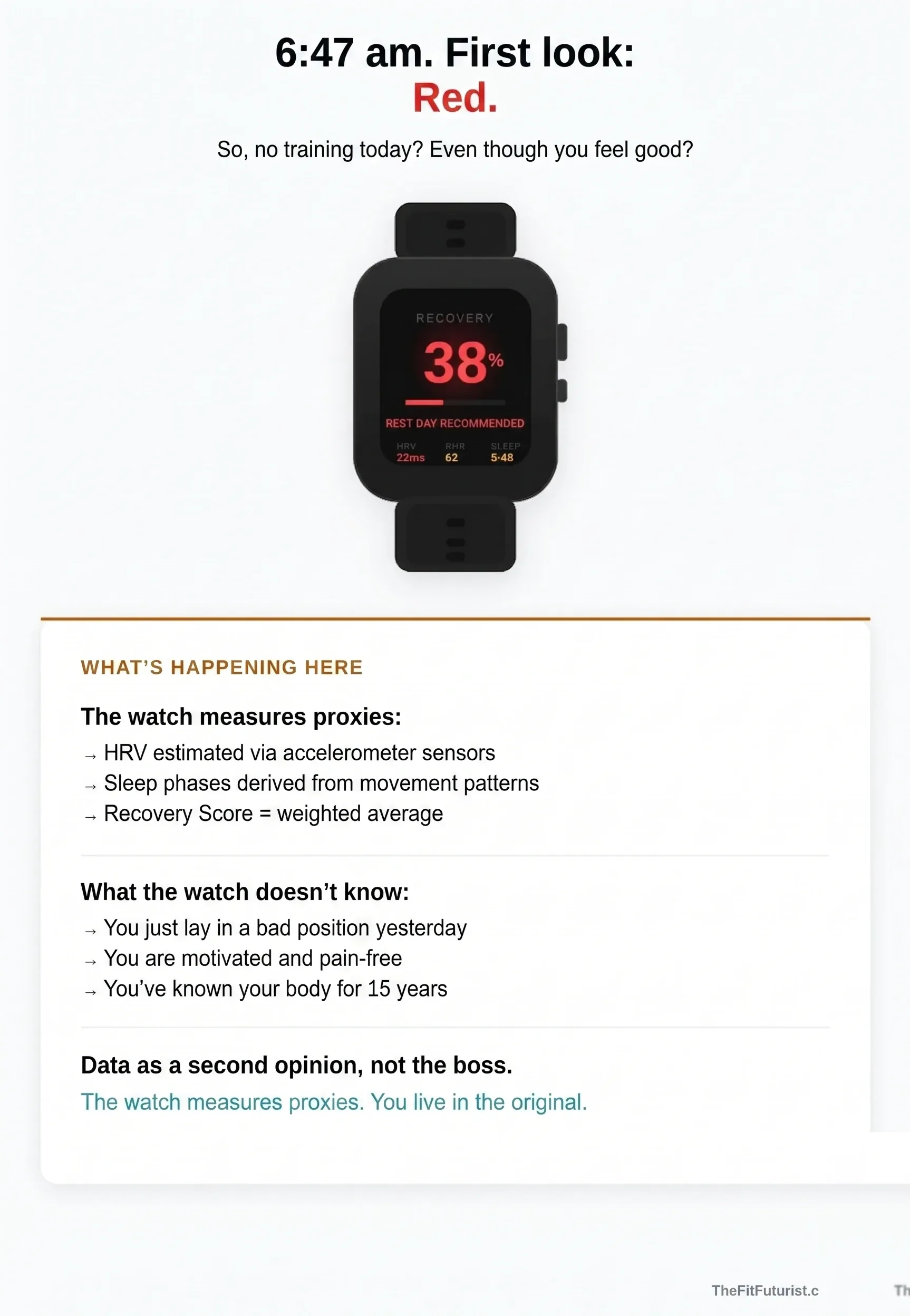
You wake up. First reach: smartphone or smartwatch. Recovery Score 38%, red. Body Battery at 22. Training recommendation: "rest day". So no training today — even though you actually feel fine.
That's algorithm dependence. And it affects more people than the manufacturers would admit. Garmin, WHOOP, Oura — all have business models based on you checking their dashboard every morning. The more often you look, the "more valuable" the product becomes. The more you adjust your behaviour to their scores, the more indispensable the watch feels.
The problem isn't the technology itself. Wearables deliver useful data — heart rate, HRV, sleep phases. The problem arises when you stop trusting your own body feedback. When a red number on the display weighs more than what you feel. When you skip a good training day because an algorithm disagrees.
The irony: anyone who has trained for years has developed a fine sense for load and recovery. In many situations this sense is more reliable than a sensor on your wrist estimating your sleep via accelerometers and deriving your "readiness" from a handful of variables. Experienced athletes know this. Beginners often only learn it after weeks of training by numbers that hold back their progress.
My approach: data as a second opinion, not the boss. If your body feedback and your Recovery Score agree — good. If they contradict, listen to your body. The watch measures proxies. You live in the original.
Algorithm vs. real AI: what's in your app?
In 2025 almost every fitness app advertises "AI-supported" features. In reality, the spectrum ranges from simple if-then rules to actual machine learning — and the app stores don't distinguish. The "AI" label has become a marketing tool, not a quality indicator.
An adaptive algorithm that reduces your training volume after three bad nights isn't the same as a neural network that recognises injury patterns from the data of 100,000 users. Both are sold as "AI". Both have different strengths and weaknesses. And both require a different level of trust.
On TheFitFuturist we consistently separate these categories. Not because it's academically interesting, but because it has practical consequences: you can trust a rule-based system if the rules make sense. You can trust an ML model if the training data were representative. And you should generally approach an LLM with healthy scepticism — no matter how convincing the answer sounds.
New training methods: it's not only tech that evolves
TheFitFuturist isn't exclusively about algorithms and apps. Training itself is changing — independently of whether AI is involved.
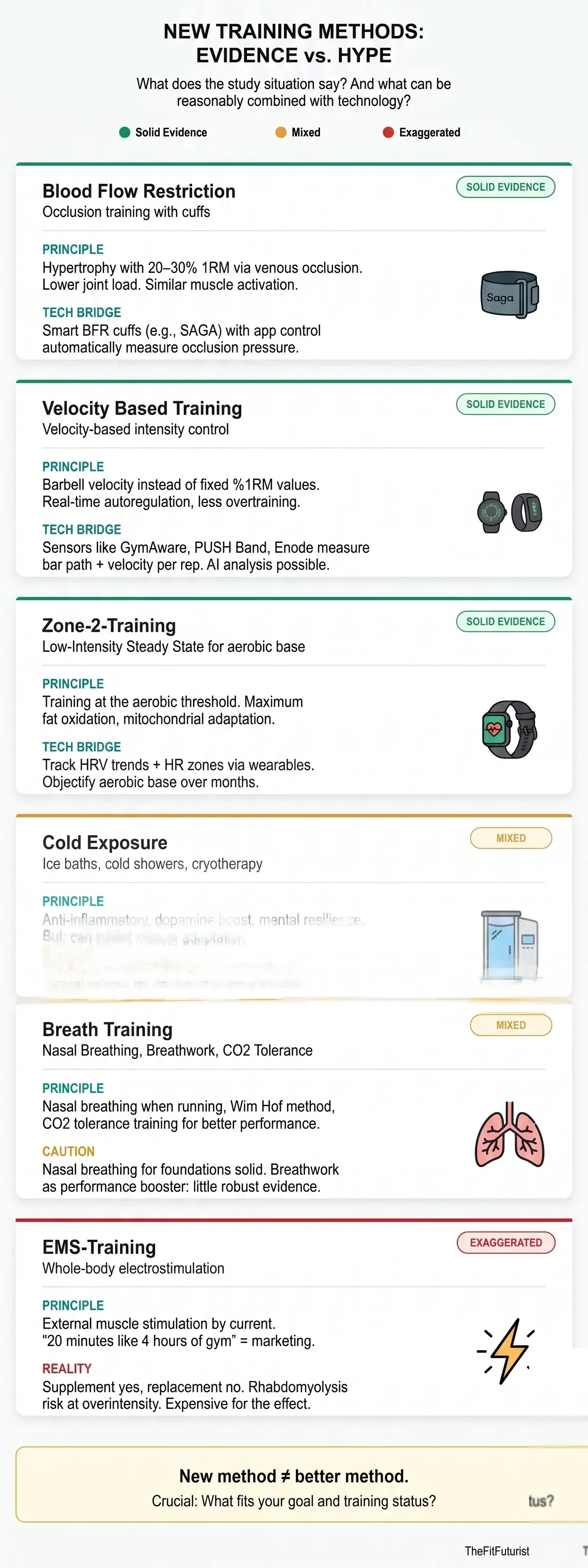
Blood flow restriction training with cuffs at 20% of maximum strength. Velocity-based training, where barbell speed controls intensity instead of a fixed percentage of 1RM. Nasal strip breathing training, Zone 2 cardio as the base for everything else, cold exposure for recovery. Some of these methods have solid evidence, some live mainly on social-media hype.
Here we classify these too. Not as a trend list, but with the question: what does the research say? Which of these actually works in practice, not just in the lab? And which can be meaningfully combined with technology — for example by tracking VBT data, or managing your Zone 2 training via HRV trends?
Because that's the point where training and technology naturally overlap: new methods produce new data, and new data enables better decisions. Provided you know what you're measuring — and why.
The common thread: tools, not replacements
Every article in this category follows one basic principle: technology is a tool, not a replacement for knowledge and experience. That sounds like a platitude, but has concrete consequences for the way we write about training here.
When an app tells you not to train today, that's information — not an instruction. When an LLM generates a training plan for you, that's a draft — not a finished program. When your HRV score is low, that's a data point — not a diagnosis.
The articles here deliver the background knowledge to classify such signals. Training knowledge, technical classification, critical assessment. Not so you distrust the technology — but so you use it better.
HANDS-ON, NOT JUST THEORY
Want to get going instead of just reading? The step-by-step guide Create a training plan with AI gives you copy-and-paste prompts for your first AI-generated plan.