Die Frage „KI oder Trainer?“ kursiert seit ChatGPT in jedem Fitness-Forum. Was dabei selten passiert: ein Blick in die tatsächliche Forschung. Dabei gibt es inzwischen eine wachsende Zahl peer-reviewter Studien, die genau das untersuchen — mit überraschend nüchternen Ergebnissen. In einem Punkt sind sich Forscher einig: Die Qualität eines KI-Trainingsplans hängt direkt davon ab, was du der KI gibst. In einem anderen Punkt ist sich die Forschung noch gar nicht einig, weil die entscheidende Frage noch niemand gestellt hat. Dieser Artikel zeigt, was die Evidenzlage wirklich hergibt — und wo die Studien aufhören.

KI vs. Trainer: Was Studien wirklich zeigen
Auf einen Blick
Mehr Kontext im Prompt bedeutet signifikant bessere KI-Pläne — das zeigt Düking et al. (2024) reproduzierbar. KI übertraf Personal Trainer beim Beantworten von Trainingsfragen, nicht beim Erstellen oder Anpassen von Plänen (D’hoe et al. 2026). Die Grundstruktur bei Krafttraining ist solide, individuelle Progression bleibt die konsistente Schwachstelle. Und die eigentliche Forschungslücke: Wie gut KI einen Plan über Wochen anpasst, hat noch niemand untersucht.
Immer auf dem Laufenden zu KI-Training & Analyse? Ein Klick – und du bekommst meine Artikel bei Google bevorzugt angezeigt.
Bei Google als bevorzugte Quelle hinzufügenWas Forschung zu KI-Trainingsplänen überhaupt misst — und was nicht
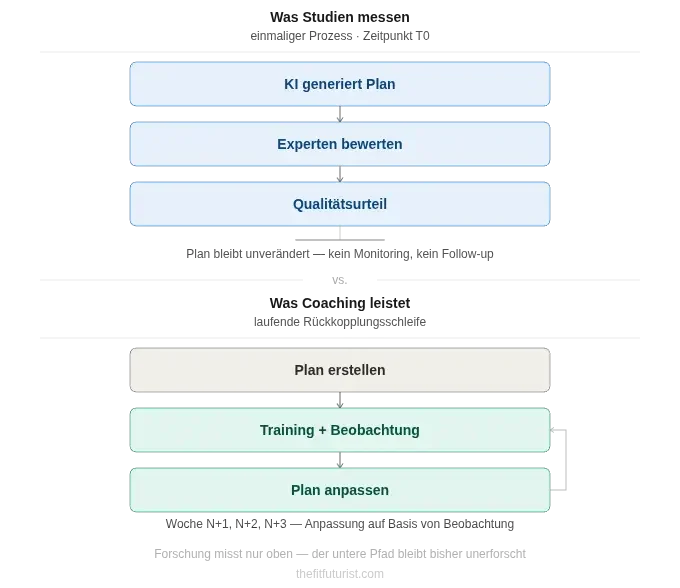
Wenn Studien die Qualität von KI-Trainingsplänen bewerten, folgen sie fast immer demselben Muster: Eine KI generiert einen Plan, Coaching-Experten bewerten ihn anhand eines Kriterienkatalogs. Manchmal werden KI-Pläne direkt mit menschlich erstellten verglichen, manchmal gegen etablierte Leitlinien (NSCA, ACSM) geprüft.
Was dabei konsequent fehlt: der Zeitverlauf. Was passiert in Woche 4, wenn der Athlet stagniert? Wer merkt, dass Schlaf und Stress eine Trainingsanpassung nötig machen? Wer plant um, wenn eine Einheit ausfällt?
Diese dynamische Dimension — das Herzstück echter Trainingsbegleitung — ist in keiner der bisher publizierten Studien Gegenstand der Messung. Die Forschung bewertet KI-Trainingspläne zum Zeitpunkt T0. Was nach T0 passiert, bleibt methodisch unbeantwortet.
Das ist keine kleine Lücke. Es ist der Unterschied zwischen einem schriftlichen Plan und echtem Coaching.
Prompt-Tiefe entscheidet: Was die Düking-Studie (2024) zeigt
Die meistzitierte Untersuchung zu diesem Thema stammt von Düking et al., publiziert 2024 im Journal of Sports Science and Medicine. Zehn Coaching-Experten bewerteten drei ChatGPT-generierte Sechswochenpläne für Läufer nach 22 Qualitätskriterien — wobei die drei Pläne aus Prompts unterschiedlicher Informationsdichte entstanden.
Das Ergebnis ist eindeutig: Plan 3, der mit den detailliertesten Angaben erstellt wurde, übertraf Plan 1 auf 15 von 22 Kriterien signifikant. Das ist kein marginaler Effekt — das ist ein struktureller Unterschied in der Planqualität.
Aber auch der beste Plan hatte eine konsistente Schwachstelle: Die Progression des Trainingsvolumens erhielt selbst beim detailliertesten Prompt eine unterdurchschnittliche Bewertung. Die Autoren hielten außerdem explizit fest, dass ChatGPT keine Rückfragen stellte — wie ein Trainer es täte, um Präferenzen, Ermüdung oder Risikotoleranz des Athleten zu erfassen.
Das ist der entscheidende Befund hinter den Zahlen: Gute Prompts verbessern KI-Pläne enorm. Aber der beste Prompt ersetzt nicht die Fähigkeit eines Trainers, im Verlauf Fragen zu stellen, die der Athlet gar nicht weiß, dass er sie hätte stellen sollen.
Ein erfahrener Trainer sammelt in den ersten Wochen Informationen, die der Athlet nie explizit kommuniziert hat — ein verändertes Bewegungsmuster, kürzere Erholungszeiten zwischen Sätzen, eine beiläufige Bemerkung über schlechten Schlaf. Genau diese Signale fehlen im Prompt — weil du sie selbst erst bemerken müsstest, um sie einzugeben.
Genau das ist der Ansatz des Claude Trainingsplan Skills: Bevor Claude irgendetwas plant, führt der Skill ein strukturiertes Assessment durch — Trainingshistorie, Ziel, Verletzungen, verfügbare Zeit, Equipment. Und es bleibt nicht beim ersten Plan: nach jeder Trainingswoche liest Claude dein Trainingslog, erkennt Muster und passt an. Derselbe Schmerz zweimal triggert eine Planmodifikation, dreimal eine Empfehlung zum Physiotherapeuten. Ob das in der Praxis so funktioniert wie gedacht — das muss sich noch zeigen. Deshalb: Skill nutzen, Feedback geben, und mithelfen ihn besser zu machen.
Der bleibende Unterschied zu einem menschlichen Trainer ist feiner: Der Skill reagiert auf das, was du einträgst. Ein erfahrener Trainer beobachtet auch das, was du gar nicht kommunizierst — ein verändertes Bewegungsmuster, kürzere Pausen zwischen Sätzen, eine beiläufige Bemerkung über schlechten Schlaf. Diese Signale fehlen im Log, weil du sie selbst erst bemerken müsstest.
KI übertrifft Trainer — aber bei Fragen, nicht bei Plänen
Eine Studie aus dem Jahr 2026, publiziert ebenfalls im Journal of Sports Science and Medicine, lieferte vielbeachtete Ergebnisse: ChatGPT schnitt in einem direkten Vergleich mit neun menschlichen Personal Trainern (EQF Level 4) in 6 von 9 Fragen besser ab — bewertet nach wissenschaftlicher Korrektheit, Verständlichkeit und Umsetzbarkeit. In keiner einzigen Frage übertrafen die Trainer die KI.
Das klingt vernichtend für die Trainerseite. Methodisch ist aber entscheidend, was hier gemessen wurde: D’hoe et al. (2026) testeten die Fähigkeit, häufige Trainingsfragen zu beantworten — nicht Pläne zu erstellen, zu monitoren oder anzupassen. ChatGPT als Informationsquelle übertrifft den durchschnittlichen Personal Trainer beim evidenzbasierten Abruf von Trainingsempfehlungen. Das ist ein echter und relevanter Befund.
Was er nicht belegt: dass KI einen guten individuellen Trainingsplan erstellt, über Wochen begleitet oder Warnsignale erkennt.
Studie | Was wurde gemessen | Ergebnis |
|---|---|---|
D’hoe et al. 2026 | KI vs. Trainer: häufige Trainingsfragen | KI in 6 von 9 Fragen besser bewertet |
Düking et al. 2024 | ChatGPT-Laufpläne nach Prompt-Tiefe | Mehr Input = signifikant bessere Planqualität |
Washif et al. 2024 | ChatGPT-Kraftprogramme vs. NSCA-Leitlinien | Grundstruktur konform, Feinabstimmung nötig |
Genç et al. 2025 | ChatGPT-3.5, 4o und 4.1 im Vergleich | Struktur okay, individuelle Anpassung limitiert |
Krafttraining mit KI: Struktur ja, Progression mit Vorbehalt
Washif et al. (2024) ließen GPT-3.5 und GPT-4 zwölfwöchige Kraftprogramme für hypothetische Probanden erstellen und verglichen sie mit NSCA-Leitlinien. Das Grundurteil: Die Programmstruktur war solide. Progressive Überlastung, Trainingsfrequenz und Phaseneinteilung lagen im erwarteten Rahmen. GPT-4 schnitt dabei deutlich besser ab als GPT-3.5 — mehr Kontextbewusstsein, feinere Unterscheidung zwischen Trainingsniveaus.
Was schwächelte: GPT-3.5 empfahl über alle Trainingsphasen hinweg gleiche Pausenzeiten — ein Spezifitätsfehler, der in einem echten Programm suboptimal wäre. Keine der Modellversionen adressierte außerdem systematisch den Abstand zur Muskelversagen, der in der modernen Hypertrophie-Forschung als relevante Steuerungsgröße gilt.
Genç et al. (2025) verglichen drei ChatGPT-Versionen (3.5, 4o, 4.1) bei ähnlichem Studiendesign. Fazit: Auch neuere Modelle zeigen Limitierungen, profitieren aber stark von strukturierten, prinzipienorientierten Prompts. Für Standardpopulationen ist die Ausgabe verwertbar — für Fortgeschrittene mit spezifischen Zielen bleibt menschliche Expertise ein echter Mehrwert.
Was Studien nicht messen — der blinde Fleck der Forschung
Alle bisher publizierten Studien teilen ein Design-Merkmal: Sie messen den KI-Trainingsplan zum Zeitpunkt seiner Erstellung. Ein Experte bewertet, ob der Plan gut ist. Fertig.
Was niemand gemessen hat: Wie verhält sich KI, wenn der Athlet nach drei Wochen nicht den erwarteten Fortschritt macht? Wenn sich Schlaf, Stress oder Lebensumstände verändern? Wenn eine leichte Verletzung das Programm über Wochen verändert?
Düking et al. (2024) haben das implizit benannt: ChatGPT stellte keine Rückfragen. Das ist kein Bug — das ist ein strukturelles Merkmal des Mediums, das die bisherige Forschung nur beim Erstellen des Plans misst, nicht beim Navigieren durch die Realität danach.
Die Frage „Kann KI einen Trainingsplan so gut anpassen wie ein Trainer?“ ist wissenschaftlich unbeantwortet. Nicht weil die Antwort unklar ist, sondern weil noch niemand eine longitudinale Studie mit diesem Design durchgeführt hat. Das ist die größte offene Forschungslücke im gesamten Bereich der KI-Trainingsplanung.
Was die Evidenzlage konkret bedeutet — und wo sie aufhört
Die Studienlage ist jung, methodisch heterogen und deckt einen kleinen Ausschnitt der Trainingsrealität ab. Was sie trotzdem klar zeigt: KI-generierte Trainingspläne können bei Standardpopulationen und guten Prompts eine solide Erststruktur liefern — reproduzierbar über mehrere Studien hinweg.
Was dabei systematisch unterschätzt wird: Der Nutzen von KI-Trainingsplänen hängt direkt von der Kompetenz des Nutzers ab. Wer die Grundlagen der Trainingsplanung versteht, gibt bessere Prompts ein — und bewertet den Output kritisch genug, um Fehler zu erkennen. Das ist kein Zufall, das ist der Kern des Prompt-Paradoxons: Die KI ist so gut wie das Wissen, das du ihr gibst.
Was die Forschung außerdem zeigt: Der Abstand zwischen guter KI-Planung und menschlichem Coaching ist beim initialen Plan kleiner als viele erwarten. Wie groß er über acht oder zwölf Wochen ist, wenn echte Anpassung gefragt ist — das weiß die Wissenschaft schlicht noch nicht.
Wenn du mit einem selbst erstellen KI-Trainingsplan starten willst, ist das der Ausgangspunkt — nicht als Abkürzung zum Nachdenken, sondern als Werkzeug mit dem du weißt umzugehen. Wer direkt einsteigen will: Trainingsplan kostenlos erstellen — Assessment inklusive.
Häufige Fragen
Welche Studien vergleichen KI-Trainingspläne mit menschlichen Trainern direkt?
Die aktuell relevantesten Studien sind Düking et al. (2024) zu ChatGPT-Laufplänen (JSSM, DOI: 10.52082/jssm.2024.56), D’hoe et al. (2026) zum Vergleich von Trainingsfragen (JSSM, PMC12912680), Washif et al. (2024) zu Kraftprogrammen (Biology of Sport, DOI: 10.5114/biolsport.2024.132987) und Genç et al. (2025) zum Vergleich verschiedener ChatGPT-Versionen (BMC Sports Sci Med Rehabil, DOI: 10.1186/s13102-025-01409-7). Alle sind open access verfügbar.
Sind KI-Trainingspläne schlechter als von Trainern erstellte?
Das hängt vom Kriterium ab. Bei standardisierten Strukturen (Frequenz, Volumen, Phasierung) liefern moderne KI-Modelle mit guten Prompts solide Ergebnisse. Bei individueller Anpassung über Wochen gibt es keine belastbaren Daten — diese Frage wurde noch nicht untersucht.
Warum ist die Prompt-Qualität so entscheidend?
Alle Studien zeigen konsistent: Mehr und präzisere Information im Prompt führt zu signifikant besserer Planqualität. KI arbeitet ausschließlich mit dem, was du eingibst. Wer die Grundlagen der Trainingsplanung kennt, kann präzisere Prompts schreiben — und bekommt präzisere Ergebnisse.
Gibt es Studien zur langfristigen KI-Trainingsbegleitung?
Nein. Das ist die größte offene Lücke in der aktuellen Forschung. Bisher wurde ausschließlich die initiale Planqualität zum Erstellungszeitpunkt untersucht — die Anpassungsleistung über Wochen und Monate bleibt methodisch unerforscht.


