A Spanish research team has reviewed the current state of wearable biosensors and machine learning systems in sports training in a comprehensive overview – 188 studies from 16 years of research. The conclusion is sober: the technology delivers usable data and ML models can support training adjustments – but autonomous coaching? We are a long way from that.

188 studies, one verdict: Good data – but no AI coach
At a glance
A new review study (188 studies, 2010–2026) shows: wearable biosensors capture physiological, biomechanical and biochemical data reliably – provided the calibration is right. In many studies, ML models outperform classical metrics when it comes to training adjustment and recovery assessment, especially in controlled settings. But: motion artefacts, missing psychological factors and poor transferability between lab and field remain real weaknesses of the technology. The authors recommend human-AI collaboration rather than autonomous systems.
Stay on top of AI training & analysis? One click — and Google shows you my articles first.
Add as a preferred source on GoogleWhat the study investigated
Madrigal-Cerezo, Domínguez-Sanz and Martín-Rodríguez systematically evaluated studies from four major databases for their paper published in Biosensors, covering the period from 2010 to 2026. Of 826 identified records, 188 studies remained after screening and duplicate removal. The focus was on three questions: how well do wearable sensors actually measure? How reliable are the ML models built on top of them? And under what conditions does the whole setup work in practice?
To answer them, the team built an evidence map comparing sensor types, study size, experimental settings (lab vs. field), model types and validation protocols. The long observation window makes the work particularly interesting: the authors trace the evolution from simple step counters and chest straps to multimodal biosensor systems with integrated AI – and can therefore classify what has genuinely improved and where industry promises are running ahead of reality.
What works
According to the review, wearable biosensors can reliably capture three categories of training data: physiological markers such as heart rate variability (HRV – a load and recovery marker that reflects the activity of your autonomic nervous system), biomechanical signals via inertial sensors and electromyography (EMG – measuring the electrical activity of your muscles), and biochemical parameters such as lactate or electrolyte levels in sweat.
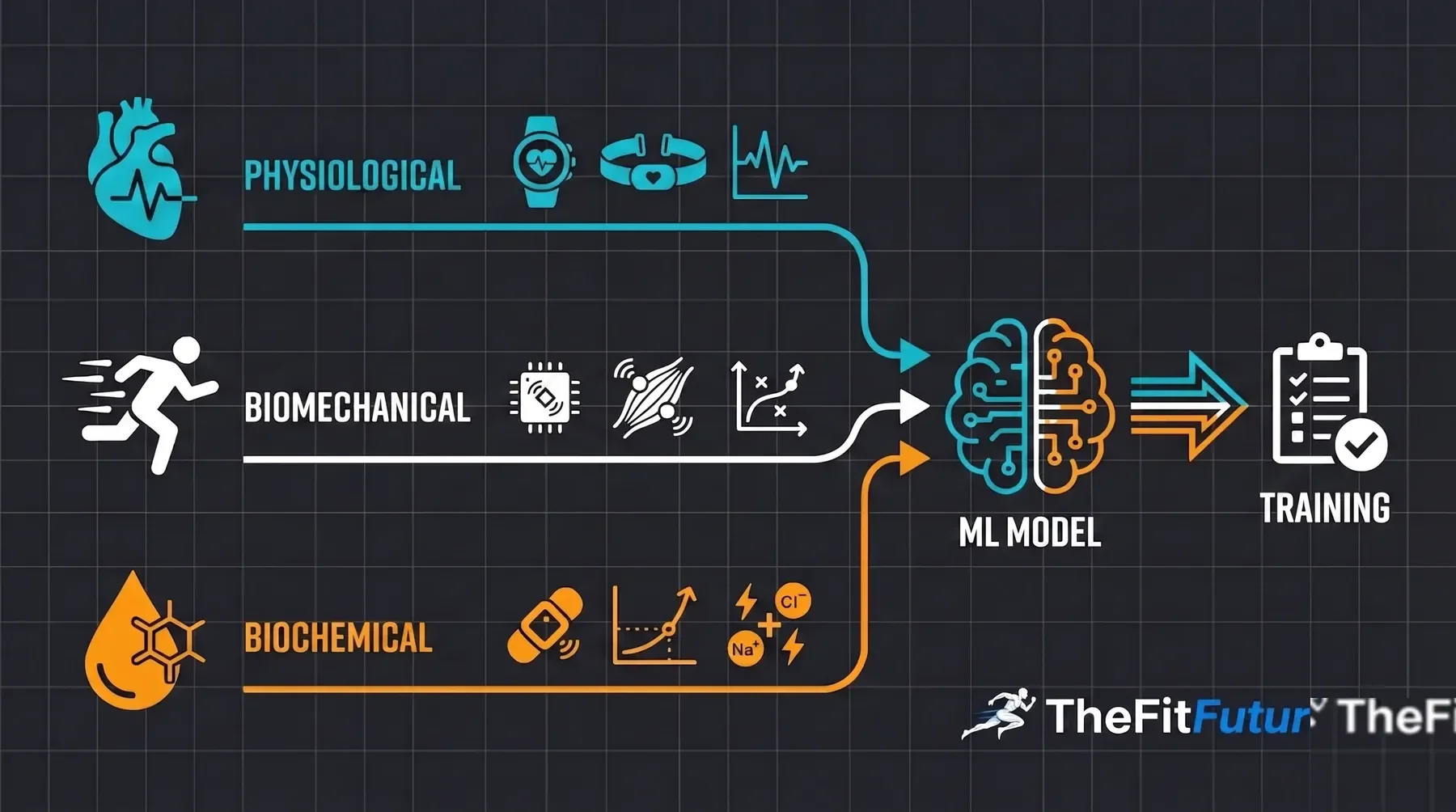
From sensor data to training recommendation: physiological, biomechanical and biochemical wearable data as input for ML models.
ML models trained on this sensor data outperform classical load metrics in many of the reviewed studies when predicting recovery readiness and performance development. This is particularly true when multiple sensors are combined and athletes are observed over a longer period. In individual controlled studies, wearable-guided training led to improved HRV recovery and more stable performance – but under optimal conditions, not in the chaotic reality of everyday training.
SWEAT LACTATE AS A MARKER
An interesting detail from the review: the first wearable sweat sensors reach a high correlation with blood lactate values in the studies evaluated. Non-invasive lactate monitoring during training is therefore getting closer – but it does not yet reliably replace a full performance diagnostic, because temperature, sweat rate and calibration still fluctuate too strongly under field conditions. That the direction is right is also shown by a recently presented sweat patch that can measure the inflammation marker CRP.
Where the technology hits its limits
The review identifies four recurring weaknesses of wearable-ML systems – not of the study itself, but of the technology in practice. PPG sensors (photoplethysmography – the green LEDs on your sports watch) at the wrist suffer from motion artefacts and fluctuations in blood flow. EMG electrodes show strong variability between measurement sessions due to sweat and placement differences. Biochemical sweat sensors react sensitively to temperature and pH. And IMU data (accelerometers) drift over time and behave differently in the lab than on the field.
WHEN THE ALGORITHM GETS IT WRONG
The review describes cases in which AI systems overestimate recovery readiness because important factors such as sleep quality or psychological stress are missing from the model. The consequence: training is intensified too early and performance collapses short-term. That is exactly what happens when algorithms decide without context – and exactly why a wearable alone is not enough.
The study explicitly emphasises: errors at the sensor level propagate through the entire pipeline – from signal processing through feature extraction to the training recommendation. Or more simply: a poorly calibrated sensor at your wrist can lead the algorithm to recommend an interval session even though your body needs rest.
Assessment: what does this mean for you?
The central insight of this study confirms what already applies in training practice: data alone trains no one. ML models are strong as decision support – they spot trends in HRV curves, estimate recovery times and can flag overtraining earlier than your gut feeling. But they fail as soon as context is missing: stress at work, bad sleep because of the kids, an incoming infection. No sensor captures that.
If you collect HRV data via Polar, Garmin or Oura and run your own analyses, you are already ahead of any app's “autonomous AI coach” – because you supply the context no algorithm has. The study calls this “human-AI collaboration” and thereby describes exactly the approach we follow here: you use AI tools for data analysis, but the interpretation stays with you.
The authors also provide a convincing argument from elite sport: even with all this technology, top athletes continue to work with human coaches. Not out of nostalgia, but because emotional understanding, ethical judgement and individual support – especially in situations such as return-to-play after injury or under mental strain – cannot be delivered by any algorithm. How difficult autonomous coaching is in practice is also shown by the fact that Apple recently scaled back its planned AI health coach.
THE PROMPT PARADOX IN ACTION
The study indirectly confirms the prompt paradox: ML models deliver better results when fed with context-rich data. Just as an LLM only gives answers as good as the question behind them, wearable algorithms are only as good as the data quality and the user's ability to interpret that data.
Looking ahead: digital twins and LLM coaches
The review also looks beyond classical wearable data at two developments. First: digital twins – virtual replicas of an athlete fed with sensor data in real time. Early pilot applications in basketball show potential for tactical decision-making, but are still in an early research stage. Second: LLM-based coaching chatbots that can deliver context-sensitive and motivating responses – with the clear caveat that their internal decision processes remain opaque and that they tend toward hallucinations and inconsistent answers.
Both are interesting directions, but the study stays honest here: the maturity level is far from everyday use. And while LLM coaches can provide informal support, they do not take responsibility for bad decisions.
Open questions
Despite the breadth of the review, some questions remain open. Long-term studies are missing on whether ML-based training adjustments actually lead to better results over months than traditional periodisation with experienced coaches. The integration of psychological and contextual data also remains an unsolved problem.
On top of that: the study explicitly calls for better reporting standards for ML models in training. Many studies test their models only within their own dataset rather than on new athletes or in different settings – which leads to overly optimistic results that do not hold up in everyday use.
Source
Madrigal-Cerezo R, Domínguez-Sanz N, Martín-Rodríguez A. Wearable Biosensing and Machine Learning for Data-Driven Training and Coaching Support. Biosensors (Basel). 2026;16(2):97. doi:10.3390/bios16020097 – PubMed | Full text (PMC)


