You look at your watch in the morning, see a low HRV and ask yourself: easy day or push through anyway? A new study shows how a system that learns by trial and error — no rulebook, no chatbot — takes exactly this decision.
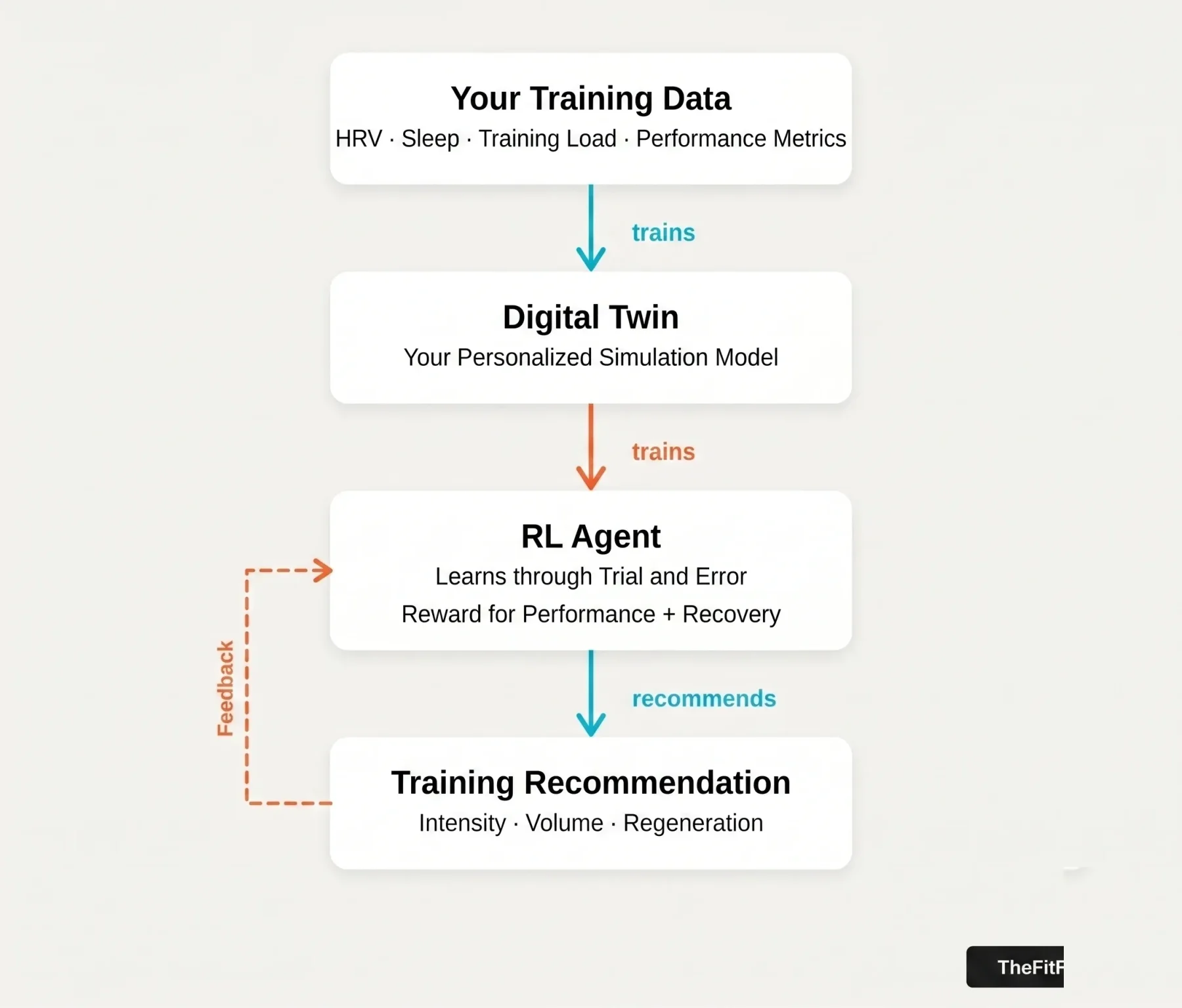
It gets your training data, simulates how you as a person respond to different loads, and develops a strategy from that which fits you.
At a glance
Chinese researchers have built a system that — unlike a chatbot or a fitness app — doesn't work with fixed rules, but learns by trial and error: it tries out training strategies on the digital twin of an athlete, gets feedback, and develops its own decisions over time. The input data is HRV, sleep and weekly performance values — exactly what your wearable records anyway. The interesting part: it is rewarded for performance and for recovery at the same time. It hasn't been tested on real athletes yet, but the approach shows where things are heading.
Stay on top of AI training & analysis? One click — and Google shows you my articles first.
The problem: two training strategies can't be tested simultaneously on the same person
If you really want to know which load strategy works better, you quickly hit a methodological limit: you can't run two approaches in parallel. At group level it does work — group A trains one way, group B differently — but then you lose the individual significance.
What holds for the group average says little about how you personally respond to a higher training frequency or more volume.
Qi Zhang, Qing Wang and Yonggang Niu from AnYang Normal University (China) solved the problem differently: instead of testing real athletes, they built a simulation model. The model was trained with data from 25 track and field athletes over a full season and learns how different training loads affect HRV, sleep and performance.
The researchers call this a "digital twin" — a virtual model that simulates how this one specific athlete responds to different loads. Not athletes in general, but with the individual patterns of this person. The agent can then try out as many strategies as it wants on the model — without having to wait for the real person.
How the system works: your data trains a digital twin — the RL agent learns on it and returns recommendations.
How the system decides: reward for good decisions, penalty for bad ones
The principle behind it is called reinforcement learning. The agent observes the athlete's current state, makes a decision — increase intensity, increase volume or actively recover — and gets a rating for it. Good decision: positive feedback. Bad decision: negative.
After thousands of such cycles, the system has developed a sense of which strategy makes sense in which situation. What the agent sees is manageable: HRV, sleep quality, the current training load relative to the past few weeks, and weekly performance development.
This isn't lab diagnostics — this is what Garmin, Polar or Whoop record anyway. Theoretically, such a system could work with the data every ambitious self-trainer already has today.
The key design trick: the system is rewarded for both
The most interesting element is the reward structure. Many systems of this kind collapse in practice because they only optimise for short-term maximisation — more performance now, consequences later.
Here it was deliberately built differently: the system gets a reward for performance gains and one for a healthy physiological state at the same time. Anyone who optimises at the expense of recovery loses points. That forces the agent to learn strategies that work in the long run.
Whether this actually works in practice the way it does in the model — that's the open question. In the simulation model, the system converges, injury risk drops, performance stays stable. What "stable" and "optimal" specifically mean, how exactly they are measured, which thresholds apply — that unfortunately remains vague in the paper.
What this isn't yet
The system was validated against a simulation model, not against real athletes in a controlled study. It has learned to beat the model — not proven that it improves real training decisions.
What the study calls an "optimal range" presumably means performance that stays within a defined band — so it doesn't crash and doesn't plateau — but exactly this isn't cleanly defined in the paper.
25 athletes, one season, one sport, one Chinese university: that's enough to develop a concept and show that it works in principle. It doesn't yet add up to a production-ready AI training coach.
On transferability to other sports: the principle — digital twin, reinforcement learning, dual reward function — isn't limited to track and field. Theoretically the approach works anywhere you have comparable input data. In practice, though, that means: new data, new training season, new domain adaptation.
In strength training, for example, the data basis for HRV as a control variable is considerably thinner than in endurance sports — the model would have to be trained from scratch, not simply transferred.
My take
What interests me about this work isn't the result — it's the approach. The digital twin solves a real methodological problem: you can't test two training strategies in parallel on the same person, and at group level you lose the individual significance. The simulation model makes exactly that possible — any number of variants, on a personalised model, without having to wait for real training cycles.
What this means for practice: nothing concrete yet. But it points in a direction — away from the rule-based "if HRV low, then easy day" and toward a system that learns from an athlete's individual pattern. That's a different approach from what current AI training apps do.