Du schaust morgens auf deine Uhr, siehst eine niedrige HRV und fragst dich: leichter Tag oder doch durchziehen? Eine neue Studie zeigt, wie ein System das durch Versuch und Irrtum lernt — kein Regelwerk, kein Chatbot — genau diese Entscheidung übernimmt.
Es bekommt deine Trainingsdaten, simuliert wie du als Person auf verschiedene Belastungen reagierst, und entwickelt daraus eine Strategie die zu dir passt.
Auf einen Blick
Chinesische Forscher haben ein System gebaut das — anders als ein Chatbot oder eine Fitness-App — nicht mit festen Regeln arbeitet, sondern durch Versuch und Irrtum lernt: es probiert Trainingsstrategien am digitalen Zwilling eines Athleten aus, bekommt Feedback, und entwickelt über Zeit eigene Entscheidungen. Eingangsdaten sind HRV, Schlaf und wöchentliche Leistungswerte — also genau das was dein Wearable sowieso aufzeichnet. Das Interessante: es wird gleichzeitig für Leistung und für Erholung belohnt. Auf echten Athleten wurde das noch nicht getestet, aber der Ansatz zeigt wo die Reise hingeht.
Immer auf dem Laufenden zu KI-Training & Analyse? Ein Klick – und du bekommst meine Artikel bei Google bevorzugt angezeigt.
Das Problem: Zwei Trainingsstrategien lassen sich nicht gleichzeitig an derselben Person testen
Wer wirklich wissen will welche Belastungsstrategie besser funktioniert, stößt schnell an eine methodische Grenze: Du kannst nicht zwei Ansätze parallel fahren. Auf Gruppenebene geht das zwar — Gruppe A trainiert so, Gruppe B anders — aber dann verlierst du die individuelle Aussagekraft.
Was für den Durchschnitt der Gruppe gilt, sagt wenig darüber aus wie du persönlich auf eine höhere Trainingsfrequenz oder mehr Volumen reagierst.
Qi Zhang, Qing Wang und Yonggang Niu von der AnYang Normal University (China) haben das Problem anders gelöst: statt echte Athleten zu testen, haben sie ein Simulationsmodell gebaut. Das Modell wurde mit Daten von 25 Leichtathleten über eine komplette Saison trainiert und lernt dabei, wie sich verschiedene Trainingsbelastungen auf HRV, Schlaf und Leistung auswirken.
Die Forscher nennen das einen „digitalen Zwilling“ — ein virtuelles Modell das simuliert, wie genau dieser eine Athlet auf verschiedene Belastungen reagiert. Nicht Athleten im Allgemeinen, sondern mit den individuellen Mustern dieser Person. Der Agent kann dann am Modell beliebig viele Strategien ausprobieren — ohne auf die echte Person warten zu müssen.
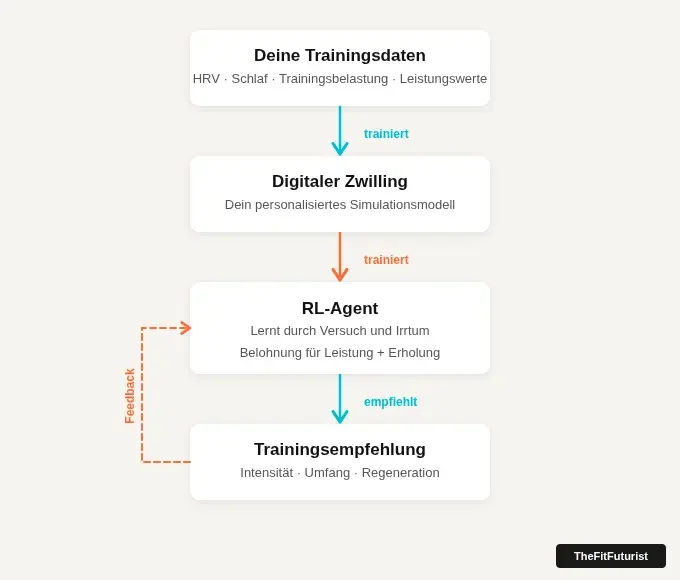
So funktioniert das System: Deine Daten trainieren einen digitalen Zwilling — der RL-Agent lernt daran und gibt Empfehlungen zurück.
Wie das System entscheidet: Belohnung für gute Entscheidungen, Strafe für schlechte
Das Prinzip dahinter heißt Reinforcement Learning — zu Deutsch: Bestärkendes Lernen. Der Agent beobachtet den aktuellen Zustand des Athleten, trifft eine Entscheidung — Intensität erhöhen, Umfang erhöhen oder aktiv regenerieren — und bekommt dafür eine Bewertung. Gute Entscheidung: positive Rückmeldung. Schlechte Entscheidung: negative.
Nach tausenden solcher Zyklen hat das System ein Gefühl dafür entwickelt, welche Strategie in welcher Situation sinnvoll ist. Was der Agent dabei sieht, ist überschaubar: HRV, Schlafqualität, die aktuelle Trainingsbelastung im Verhältnis zu den letzten Wochen, und die wöchentliche Leistungsentwicklung.
Das ist keine Labordiagnostik — das ist das was Garmin, Polar oder Whoop sowieso aufzeichnen. Theoretisch könnte so ein System also mit den Daten arbeiten, die jeder ambitionierte Selbsttrainer schon heute hat.
Der entscheidende Design-Kniff: das System wird für beides belohnt
Das interessanteste Element ist die Belohnungsstruktur. Viele Systeme dieser Art kollabieren in der Praxis weil sie nur auf kurzfristige Maximierung optimieren — mehr Leistung jetzt, Konsequenzen später.
Hier wurde das bewusst anders gebaut: das System bekommt gleichzeitig eine Belohnung für Leistungssteigerung und eine für einen gesunden physiologischen Zustand. Wer auf Kosten der Erholung optimiert, verliert Punkte. Das zwingt den Agenten dazu Strategien zu lernen, die langfristig funktionieren.
Ob das in der Praxis tatsächlich so funktioniert wie im Modell — das ist die offene Frage. Im Simulationsmodell konvergiert das System, das Verletzungsrisiko sinkt, die Leistung bleibt stabil. Was „stabil“ und „optimal“ konkret bedeutet, wie genau gemessen, welche Schwellenwerte — das bleibt in der Veröffentlichung leider vage.
Was das Ganze noch nicht ist
Das System wurde an einem Simulationsmodell validiert, nicht an echten Athleten in einer kontrollierten Studie. Es hat gelernt, das Modell zu schlagen — nicht bewiesen, dass es reale Trainingsentscheidungen verbessert.
Was die Studie als „optimalen Bereich“ bezeichnet, meint vermutlich eine Leistung die sich innerhalb einer definierten Bandbreite hält — also nicht abstürzt und nicht plateaut — aber genau das wird in der Veröffentlichung nicht sauber definiert.
25 Athleten, eine Saison, eine Sportart, eine chinesische Universität: das reicht um ein Konzept zu entwickeln und zu zeigen dass es prinzipiell funktioniert. Einen praxisreifen KI-Trainingscoach ergibt das noch nicht.
Zur Übertragbarkeit auf andere Sportarten: Das Prinzip — digitaler Zwilling, Reinforcement Learning, duale Belohnungsfunktion — ist nicht auf Leichtathletik beschränkt. Theoretisch funktioniert der Ansatz überall wo du vergleichbare Eingangsdaten hast. Praktisch bedeutet das aber: neue Daten, neue Trainingssaison, neue Domänenanpassung.
Im Kraftsport etwa ist die Datenlage für HRV als Steuerungsgröße deutlich dünner als im Ausdauerbereich — das Modell müsste von Grund auf neu trainiert werden, nicht einfach übertragen.
Meine Einschätzung
Was mich an dieser Arbeit interessiert, ist nicht das Ergebnis — sondern der Ansatz. Der digitale Zwilling löst ein echtes methodisches Problem: Du kannst zwei Trainingsstrategien nicht parallel an derselben Person testen, und auf Gruppenebene verlierst du die individuelle Aussagekraft. Das Simulationsmodell macht genau das möglich — beliebig viele Varianten, an einem personalisierten Modell, ohne auf echte Trainingszyklen warten zu müssen.
Was das für die Praxis bedeutet: noch nichts Konkretes. Aber es zeigt eine Richtung — weg vom regelbasierten „wenn HRV niedrig, dann leichter Tag“ und hin zu einem System das aus dem individuellen Muster eines Athleten lernt. Das ist ein anderer Ansatz als das was aktuelle KI-Trainings-Apps machen.